この章では、共通する属性値を持つレコードをどのようにグループ化するかを学びます。例えば、同じ部署で働いている従業員をグループ化するまたは、同じ日に始まったプロジェクトをグループ化します。
1. サブグループ(下位群)
会社の全ての案件(プロジェクト)および、それらのプロジェクトに参加している従業員数に関するデータが欲しいと仮定しましょう。
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
下記のような表が取得できます。
| {{h}} |
|---|
| {{r}} |
どういった仕組みになっているのでしょうか? どのようにサブグループ(下位群)は構成されるかもっと詳しく見てみましょう。まず初めに、ProjectとInvolvementの表の間でそれらの両方のデータを統合しなくてはなりません。その後、共通のプロジェクトID(案件ID)のレコードは、以下の命令分によってグループ化されます:GROUP BY pro.ID. 最後に、 COUNT(*)を用いてそれぞれのサブグループ(下位群)に含まれる要素の数(レコード)がSELECT の中に表示されます。 図7.2 は上記について示されています。
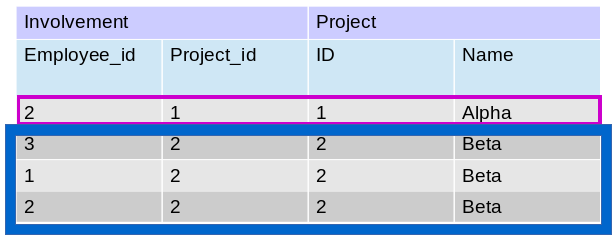
図 7.2 : SQLでにサブグループの構築
2. サブグループ(下位群)内の条件付け
従業員2人または3人が参加しているプロジェクトを抽出したいとしましょう。
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
HAVING COUNT(*) = 2 OR COUNT(*) = 3
下記の表のようになります。
| {{h}} |
|---|
| {{r}} |
まとめ
共通する属性値を保持しているレコードのグループ化の方法に関して学びました。HAVING 節と関連付けされているGROUP BYは、1つまたはそれ以上の条件を満たすサブグループ(下位群)にフィルターをかける方法です。HAVINGは、全体としてサブグループの条件を設定するのに対して、WHEREはレコードのみに対してです。
SQLによって実行される操作の順番に留意することはとても重要です。初めに、表[テーブル]は、1つの総合表を形成することによって結合されます。その表[テーブル]の後段のレコードの部分にのみ合う条件が選択されます。(WHERE)それらの残りのレコードを基に、サブグループは作成されます (GROUP BY) 最後に、それらのサブグループでの条件が確認されます。(HAVING)