Dans le présent chapitre, nous allons voir comment grouper des enregistrements qui ont une même valeur d’attribut. Par exemple, grouper les employés qui travaillent dans le même département ou encore grouper les projets qui ont commencé à une même date.
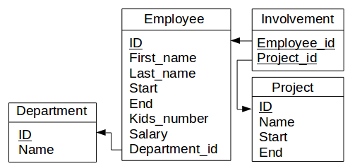
Figure 7.1 : schéma de base de données
1. Sous-groupe
Supposons que nous aimerions obtenir les données à propos des projets de l’entreprise et le nombre d’employés impliqués dans chacun.
SELECT pro.Name AS Projet, COUNT(*) AS NbEmployes
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
On obtient le tableau suivant.
| {{h}} |
|---|
| {{r}} |
Explicitons comment fonctionne cette construction de sous-groupes. D’abord nous avons agrégé les données des tables Project et Involvement avec une jointure. Le code GROUP BY pro.ID regroupe ensemble les lignes qui ont le même projet ID. Finalement, dans le SELECT, on requiert le nom du projet et le nombre d’éléments (i.e. lignes) que contient chaque sous-groupe avec COUNT(*). La Figure 7.2 illustre ce qui précède.
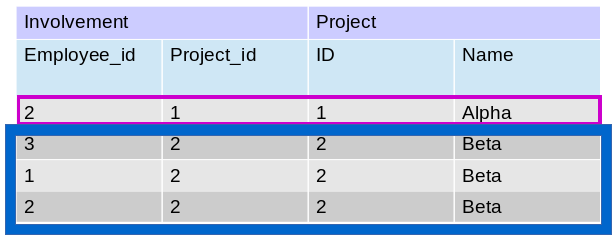
Figure 7.2 : sous-groupe en SQL
2. Condition dans les sous-groupes
Supposons que nous aimerions obtenir les données à propos des projets de l’entreprise impliquant deux ou trois employés.
SELECT pro.Name AS Projet, COUNT(*) AS NbEmployes
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
HAVING COUNT(*) = 2 OR COUNT(*) = 3
On obtient le tableau suivant.
| {{h}} |
|---|
| {{r}} |
Récap
Un sous-groupe regroupe les enregistrements qui ont un ou plusieurs attributs communs. HAVING associé à GROUP BY sert à filtrer les sous-groupes qui satisfont à une ou plusieurs conditions. HAVING pose des conditions sur un sous-groupe dans son entier alors que WHERE sur les enregistrements uniquement.
Il est très important de garder en tête l’ordre dans lequel les opérations sont effectuées par SQL. D’abord, les tables sont jointes pour former une table agrégée. Seuls les enregistrements de celle-ci satisfaisant les conditions sont retenus (WHERE). Ensuite, sur la base de ces enregistrements restants, les sous-groupes sont créés (GROUP BY). Finalement, les conditions sur les sous-groupes sont vérifiées (HAVING).