サブグループごとに上位$数$を決める必要があるとします。例としては、カテゴリーごと(ジュニア・シニアなど)のレースで上位三位のベストタイムのレーサーに関しての情報を得たいとします。 GROUP BY節では、グループごとの一行(一位)のみしか返って来ないためこのようなクエリーは出来ません。
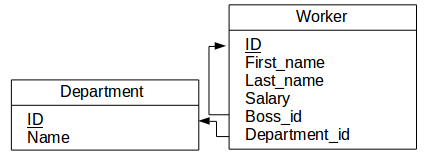
図 4.1 : データベーススキーマ
1. 和集合
各部署ごとの、給料が高い上位二人の従業員に関してのデータを取得したいとしましょう。
(SELECT * FROM Employee WHERE Department_id = 1 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 2 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 3 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 4 ORDER BY Salary DESC LIMIT 0,2)
下記の表が表示されます。
| {{h}} |
|---|
| {{r}} |
和集合 は、異なった集合の要素部分をひとまとめにする集合論からの操作です。和集合節は、その操作を実行します。
まとめ
GROUP BY は、共通の属性値を持った行を一つのグループにまとめる事を許可しますが、グループにつき一つの行のみが返されます。
UNION は、異なった集合からの要素をひとまとめにします。
UNION は、 ORDER BYで結びつき、そしてLIMIT は、グループごとの上位$数$を得るために使用することができます。(例では、$n=2$)
しかしながらこのアプローチは、2つのデメリットがあります。
- 望みのカテゴリーは、手入力でコーディングされる必要はあります。(上記の例での部署)
- 複数の同一の値は、考慮されていません。(上記の例の中で、部署内で、もし三人の従業員が同じ高額の給料な場合。)
次の章では、このアプローチのデメリットの解決のテクニックに関して説明します。