This chapter is on how to optimize correlated subqueries. The problem with correlated subqueries is that they do the same computation many times, which turns to be inefficient.
We are going to discuss about a technique combining derived table and self-join (join with the same table) for optimization purposes.
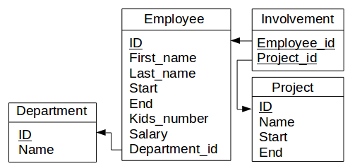
Figure 1.1 : Database schema
1. Correlated subquery
Let’s go over the example we discussed about correlated subqueries. We then wanted to get, for each department, the data about the employee having started to work the first in (most senior).
SELECT dep.Name AS Department, emp.First_name, emp.Last_name, emp.Start
FROM Employee AS emp, Department AS dep
WHERE emp.Department_ID = dep.ID AND emp.Start = (
SELECT MIN(e.Start)
FROM Employee AS e
WHERE e.Department_ID = emp.Department_ID
)
We get the following table.
| {{h}} |
|---|
| {{r}} |
2. Optimization
Let’s take the opposite approach. Instead of computing the minimal start date for a given department at each iteration in the WHERE clause, let’s compute first all minimal start dates per department and store them in a derived table. Then let’s perform a self-join for filtering by minimal start date.
The trick lies in the use of both Start and Department_id as keys for doing the self-join.
SELECT D.Name AS Department, e.First_name, e.Last_name, e.Start
FROM (
SELECT e.Department_id AS Dep_id, MIN(e.Start) AS Start
FROM Employee AS e
GROUP BY e.Department_id
) AS Min_start_by_dep, Employee AS e, Department AS D
WHERE Min_start_by_dep.Start = e.Start AND e.Department_id = Min_start_by_dep.Dep_id AND e.Department_id = D.ID
We get the following table.
| {{h}} |
|---|
| {{r}} |