この章は、 相関性があるサブクエリ の最適化の操作手順に関してです。相関性があるサブクエリの問題は、それらが何度も同じ計算をして、非効率なことです。
最適化目的のため、導出表 と自己結合:セルフジョインを結合するためのテクニックに関して見てみましょう。
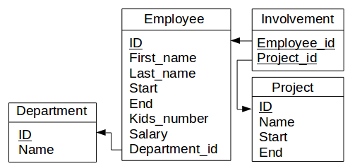
図 1.1 : データベース スキーマ
1. 相関性があるサブクエリ
相関性があるサブクエリの例に関して見てみましょう。各部署で、一番初めに働き始めた従業員に関するデーターを取得したいとしましょう。
SELECT dep.Name AS Department, emp.First_name, emp.Last_name, emp.Start
FROM Employee AS emp, Department AS dep
WHERE emp.Department_ID = dep.ID AND emp.Start = (
SELECT MIN(e.Start)
FROM Employee AS e
WHERE e.Department_ID = emp.Department_ID
)
下記の表が取得できます。
| {{h}} |
|---|
| {{r}} |
2. 最適化
逆のアプローチをしてみましょう。WHERE節で反復ごとの与えられた部署の最少の開始日を計算する代わりに、各部署の最初のの全ての最少開始日を計算して導出表に保存しましょう。そして、最少の開始日のフィルタリングによって自己結合をしてみましょう。
トリックは、自己結合をするためのキーとしてStartとDepartment_idの両方を使用することにあります。
SELECT D.Name AS Department, e.First_name, e.Last_name, e.Start
FROM (
SELECT e.Department_id AS Dep_id, MIN(e.Start) AS Start
FROM Employee AS e
GROUP BY e.Department_id
) AS Min_start_by_dep, Employee AS e, Department AS D
WHERE Min_start_by_dep.Start = e.Start AND e.Department_id = Min_start_by_dep.Dep_id AND e.Department_id = D.ID
下記の表が取得できます。
| {{h}} |
|---|
| {{r}} |
まとめ
相関性のあるサブクエリーの最適化は、 逆のアプローチをすることにあります。 反復ごと(各行で)に計算を行う代わりに、一度全てにこの計算を行って、導出表 へ結果を保存します。最後に、その導出表で自己結合をします。