In this chapter we are going to study how to group together records having an attribute’s value in common. As for instance grouping together employees working in the same department or projects having started on the same date.
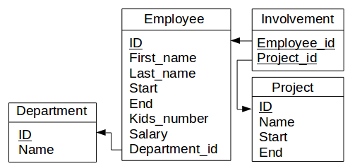
Figure 7.1 : Database schema
1. Subgroup
Let’s suppose we’d like to get data about all the company’s projects as well as the number of employees involved in each.
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
We get the following table.
| {{h}} |
|---|
| {{r}} |
How does it work ? Let’s see in more detail on how subgroups are constructed. First a join has to be done between Project and Involvement tables for aggregating their data. Then records having a common project ID are grouped together by the following statement : GROUP BY pro.ID. Finally in the SELECT, the number of elements (meaning records) each subgroup contains is asked using COUNT(*) to be displayed. Figure 7.2 illustrates the above.
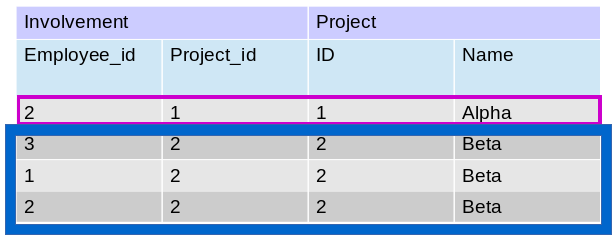
Figure 7.2 : construction of subgroups in SQL
2. Condition in subgroups
Let’s suppose we’d like to get data about projects in which two employees or three employees are involved.
SELECT pro.Name AS project, COUNT(*) AS nbOfEmployees
FROM Project AS pro, Involvement AS inv
WHERE inv.Project_id = pro.ID
GROUP BY pro.ID
HAVING COUNT(*) = 2 OR COUNT(*) = 3
We get the following table.
| {{h}} |
|---|
| {{r}} |
Recap
We studied the way to group together records having one or many attributes’ value in common. HAVING clause associated with the GROUP BY one is the way to filter subgroups satisfying one or more conditions. HAVING sets conditions on subgroups as a whole whereas WHERE on records only.
It is very important to keep in mind the order in which operations are performed by SQL. First, tables are joined by forming one single aggregated table. Only records part of that latter table meeting the stated conditions are selected (WHERE). Based on those remaining records, subgroups are created (GROUP BY). Finally, the conditions on those subgroups are checked out (HAVING).