You might need the $n$ top rows per subgroup. As an example, for a given race we’d like to get the racers who performed the 3 best times for each category (junior, senior, etc.). This kind of query cannot be done with a GROUP BY clause since that one returns only one row per group.
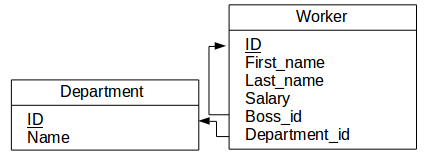
Figure 4.1 : Database schema
1. Union
Let’s assume we’d like to get data about employees having the two highest salaries for each department.
(SELECT * FROM Employee WHERE Department_id = 1 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 2 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 3 ORDER BY Salary DESC LIMIT 0,2)
UNION
(SELECT * FROM Employee WHERE Department_id = 4 ORDER BY Salary DESC LIMIT 0,2)
We get the following table.
| {{h}} |
|---|
| {{r}} |
Union is an operation from the set theory which gathers together elements part of different sets. The UNION clause implements that operation.
Recap
GROUP BY allows to group together rows having an attribute’s value in common but returns only one row per group.
UNION gathers together elements from different sets.
UNION combined with ORDER BY and LIMIT can be used for getting the $n$ top rows per group (in our example, $n=2$). This approach presents two drawbacks though.
- The wished categories need to be hand-coded (i.e. the departments in our example).
- It does not take into account multiple identical values (e.g. if three employees would have the same highest salary within a given department in our example).
The next chapter describes a technique addressing the drawbacks of the present approach.