と表[テーブル]は、いわゆる関係(リレーショナル)データベースと呼ばれる私たちが勉強するデータベースの中心概念です。
1.実体【エンティティ】
実体[エンティティ]とは、データモデルです。 実体[エンティティ]は、それ故に実在の表現です。
例を見てみましょう。 従業員に関するデータを管理したいとしましょう。 実際のデータを保存する前に、どのデータを保存することが重要かを決定しなくてはなりません。この目的によって、初めにデータモデリングが成されなくてはなりません。
会社Aは、 図2.1に描かれているデータを保存することを決めたのに対し、会社Bは、図 2.2に表示されているようなもっと簡単なデータが必要とします。 実際には、従業員に関するデータをモデル化する方法は無数にあります。

図2.1 : モデル A

図2.2 : モデル B
2.表[テーブル]
データがひとたびモデル化されたら、データベースが作成(実装)されます。実体[エンティティ]はその後、表[テーブル]によって実体化します。下記の表[テーブル]は、図 2.1で表示されている従業員の実体[エンティティ]に関係する表が図解されています。 表[テーブル]の行(ヘッダーに関係なく)は、表のレコード(またエントリー)と呼ばれます。
| {{h}} |
|---|
| {{r}} |
上の表の終了日属性について、いくつかのレコードはNULL値である。SQLは、この値はまだ不明と言っています。この場合、何人かの従業員は、まだ会社に属していて、それゆえに終了日は登録されていません。
属性IDは、特別なものです。それは、表[テーブル]の主キーです。その役割は、表[テーブル]でレコードを区別することを可能にします。部署IDの属性もまた特別なものです。これは、いわゆる外部キーで、他の表[テーブル]とのコネクタの役割をします。今回のケースにおいて、それは各従業員が働いている部署に関連づけられています。
3.データベーススキーマ
データベーススキーマは、データベースの全ての表[テーブル]およびそれらの表[テーブル]間の関係を表します。前章で紹介したデータベーススキーマは、従業員、部署、プロジェクト、配属の名の4つの表を含む図2.3で描かれています。それぞれが、それぞれの属性(名前、苗字、…)を持っています。主キーには、下線がひいてあります。2つの表[テーブル]の関連付けが、矢印で描かれています。
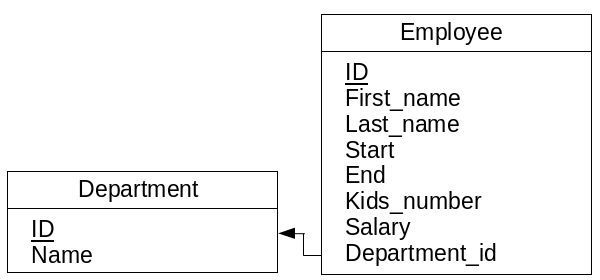
図 2.3 : 基本のデータベーススキーマ
まとめ

図 2.4 : モデリング (出典元: platinumtraining.org)

図 2.5 : 実装 (出典元: haskell.com)
データベース開発では、2つの分離層が区別される必要があります。
最初のは、どのデータが関連性があり、どのようにデータが相互に結び付けられるかについてです。このフェーズ(段階)は、デザインと呼ばれます。実体[エンティティ]のモデル化、それらの属性や実体[エンティティ]間の関係はその一部です。 図 2.4で描かれているそのフェーズ(段階)は、このコースの範囲を超えています。
2番目のものは、実データに関してです。 図 2.5に描かれているそのフェーズ(段階)は、実装(または実現)と呼ばれ、それから各実体[エンティティ]は、表によって実現化されてます。表[テーブル]の行は、レコードと呼ばれます。主キーは、お互いを識別しやすくします。このコースは、その2番目のフェーズ(段階)に重点を置いています。