Sometimes it is necessary to do a SQL query within another one. This concept is the so-called subquery and this chapter aims to discuss on how and why to deal with it.
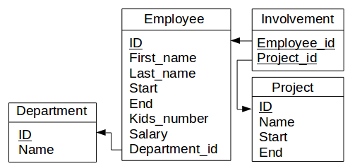
Figure 8.1 : Database schema
1. Independent subquery
Let’s assume we’d like to get data about all employees whose salary is higher or equal to the average salary of all employees.
SELECT emp.First_name AS firstName, emp.Last_name AS lastName, emp.Salary
FROM Employee AS emp
WHERE emp.Salary >= (
SELECT AVG( e.salary )
FROM Employee AS e
)
We get the following table.
| {{h}} |
|---|
| {{r}} |
2. Correlated subquery
Let’s assume we’d like to get, for each department, the data about the employee having started to work the first in (most senior).
SELECT dep.Name AS Department, emp.First_name, emp.Last_name, emp.Start
FROM Employee AS emp, Department AS dep
WHERE emp.Department_ID = dep.ID AND emp.Start = (
SELECT MIN(e.Start)
FROM Employee AS e
WHERE e.Department_ID = emp.Department_ID
)
We get the following table.
| {{h}} |
|---|
| {{r}} |
Recap
Subqueries are used when a piece of data needs to be obtained first, on which the filtering is based.
In the first example above, the average salary of all employees needs first to be obtained. This is done by the subquery as follows :
SELECT AVG( e.salary )
FROM Employee AS e
A subquery is said to be correlated when the subquery relates to the main query. In the second example above, for each employee, the subquery gives the oldest start date among employees part of the current employee’s department. Therefore, the subquery depends on the current employee’s department. That dependence is stated as follows :
e.Department_ID = emp.Department_ID